
IL NUMERO DI APRILE 2025 in edicola

IL NUMERO DI APRILE 2025 in edicola

IL NUMERO DI APRILE 2025 in edicola

IL NUMERO DI APRILE 2025 in edicola

IL NUMERO DI APRILE 2025 in edicola

IL NUMERO DI APRILE 2025 in edicola
IL NUMERO DI APRILE 2025 in edicola
IL NUMERO DI APRILE 2025 in edicola
IL NUMERO DI APRILE 2025 in edicola
IL NUMERO DI APRILE 2025 in edicola
IL NUMERO DI APRILE 2025 in edicola
IL NUMERO DI APRILE 2025 in edicola


Verifica le date inserite: la data di inizio deve precedere quella di fine








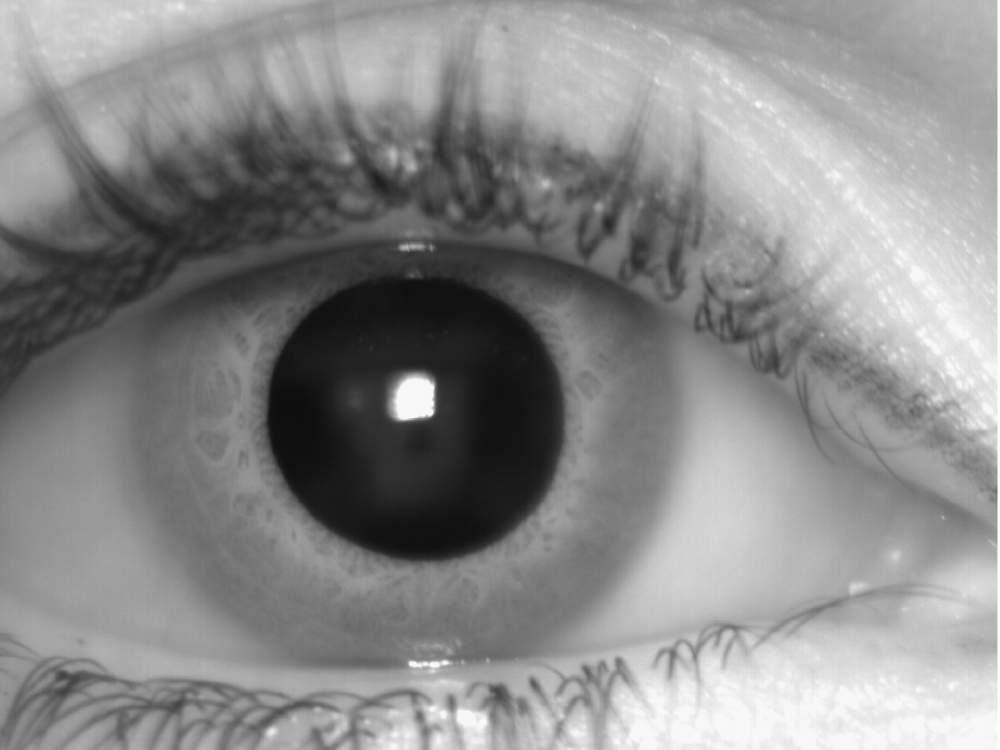
«Sdumla-Hmt», 2011 Yilong Yin, Lili Liu e Xiwei Sun. Le impronte digitali e le scansioni dell’iride provengono da un set di dati multimodali sviluppato dall’università di Shandong a Jinan, in Cina, che include volti, iridi, vene delle dita e impronte digitali utilizzati in biometrica
Da Prada tutti schedati nell’album fotografico del mondo
L’indagine di Paglen e Crawford sulle immagini e l'uso che ne fa l’Intelligenza Artificiale

Due personalità dai molti e diversi talenti, come Kate Crawford, docente della New York University (una fra gli studiosi internazionalmente più riconosciuti di Big Data e di Intelligenza Artificiale) che è anche un’artista, e Trevor Paglen, lui artista di grande caratura ma anche giornalista investigativo, scrittore, studioso d’ingegneria e di altre complesse discipline, hanno unito i loro saperi per realizzare la mostra fotografica «Training Humans» (dal 12 settembre al 24 febbraio nella sede di Osservatorio in Galleria della Fondazione Prada), dedicandosi alle immagini usate per «insegnare» ai sistemi di Intelligenza Artificiale (IA) come vedere e classificare il mondo.
Non dunque una riflessione sulle funzioni e gli obiettivi dell’IA, bensì un’indagine sulle fotografie utilizzate da questi «motori della visione», sul loro funzionamento e utilizzo all’interno di programmi che coinvolgono istruzione, sanità, sorveglianza militare, prevenzione del crimine e gestione delle risorse umane e del sistema penale. Con tutte le implicazioni etiche e sociologiche che tali usi comportano: evidente, infatti, che la loro applicazione può essere viziata da pregiudizi e interferenze ideologiche, poiché, come spiegano, «nella computer vision e nei sistemi di IA i criteri di misurazione si trasformano facilmente, ma in modo nascosto, in strumenti di giudizio morale».
E poiché quello che a noi profani appare come il frutto della più attuale tecnologia informatica è, al contrario, una creatura più che cinquantenne (i primi esperimenti in laboratorio di riconoscimento facciale computerizzato, promossi negli Stati Uniti dalla Cia, risalgono al 1963), la mostra, che sembrerebbe votata alla sincronia, è invece ordinata con un percorso diacronico, partendo proprio da quelle lontane immagini e proseguendo attraverso le successive, elaborate con le nuove generazioni di computer che, dagli anni ’90, hanno permesso di affinare le indagini, fino alle realtà sbalorditive di oggi.
Se all’inizio il «benchmark standard» che avrebbe permesso ai ricercatori di creare gli algoritmi di riconoscimento facciale si fondava su circa 14mila ritratti di 1.199 individui, con il diffondersi di internet e dei social media il serbatoio d’immagini si è ingigantito esponenzialmente (liberandosi, poi, da ogni vincolo di privacy) e ha permesso ai tecnici di produrre un sistema potenzialmente illimitato di classificazione delle persone sulla base di razza, età, genere, emozione, salute mentale o altro: un processo di cui non sfuggono le implicazioni politiche, dettate da modelli «postcoloniali e razzisti di segmentazione demografica».
Da parte sua, la classificazione delle espressioni facciali ha offerto parametri su cui le aziende possono basarsi per valutare l’affidabilità degli aspiranti a un posto di lavoro. Si è così formata un’asimmetria di potere, che i due artisti sperano di combattere anche con questa mostra, di cui contano di fare «il punto di partenza per iniziare a ripensare tali sistemi e per comprendere in modo scientifico come ci vedono e ci classificano».
«Sdumla-Hmt», 2011 Yilong Yin, Lili Liu e Xiwei Sun. Le impronte digitali e le scansioni dell’iride provengono da un set di dati multimodali sviluppato dall’università di Shandong a Jinan, in Cina, che include volti, iridi, vene delle dita e impronte digitali utilizzati in biometrica
Ada Masoero, 11 settembre 2019 | © Riproduzione riservata

